Maximiser le ROI avec l'IA générative :
Un guide stratégique pour les dirigeants d'entreprise
L'IA générative est passée d'une nouveauté à l'élément moteur des opérations commerciales modernes. D'ici 2026, il ne s'agit plus seulement de chatbots ; il s'agit d'agents autonomes, de flux de travail automatisés et de synthèse de données à grande vitesse. Mais comment cette technologie fonctionne-t-elle réellement en coulisses, et comment votre organisation peut-elle l'exploiter en toute sécurité ?
Qu'est-ce que l'IA générative en 2026 ?
L'IA générative est une sous-catégorie de l'intelligence artificielle conçue pour créer du contenu original — allant du texte et du code à des images haute fidélité et des données synthétiques. Contrairement à l'"IA discriminative" traditionnelle, qui se contente de classer les données existantes, l'IA générative utilise des réseaux neuronaux avancés pour reconnaître les motifs sous-jacents et synthétiser des résultats entièrement nouveaux qui imitent la créativité et la logique humaines.
Pour les entreprises, cela se traduit par des gains massifs en scalabilité, permettant aux équipes d'automatiser des tâches cognitives complexes qui nécessitaient auparavant une intervention manuelle.
Comment fonctionne l'IA générative ? (L'architecture LLM)
L'IA générative moderne est principalement alimentée par les grands modèles de langage (LLMs). Initialement introduits par l'article de Google "Attention is All You Need", ces modèles fonctionnent comme des moteurs probabilistes sophistiqués. Lorsque vous fournissez une invite, le modèle calcule la probabilité du prochain "jeton" (mot ou fragment) en se basant sur les trillions de points de données qu'il a traités lors de l'entraînement. Il ne "connaît" pas les faits au sens humain ; il prédit la continuation la plus logiquement statistique de votre pensée.
Transformers et fenêtres contextuelles : le "cerveau" de l'IA
L'architecture Transformer est ce qui permet à l'IA de comprendre le contexte. Contrairement aux modèles plus anciens qui lisaient le texte de manière linéaire, les Transformers utilisent des « mécanismes d'attention » pour examiner un document entier simultanément.
Pour les CTO, le concept le plus crucial aujourd'hui est la fenêtre contextuelle. Cela détermine la quantité d'informations que l'IA peut "garder en mémoire" pendant une conversation. Les modèles modernes supportent désormais des fenêtres massives, vous permettant de télécharger des documentations techniques complètes ou des bases de code pour que l'IA les analyse sans perdre de vue les instructions initiales. C'est là que le Prompt Engineering devient une compétence à fort effet de levier — structurer votre entrée pour orienter l'attention du modèle.
Pour maximiser la qualité de votre production, utilisez notre Optimiseur de Prompt ChatGPT pour affiner vos instructions et obtenir des résultats de qualité professionnelle.
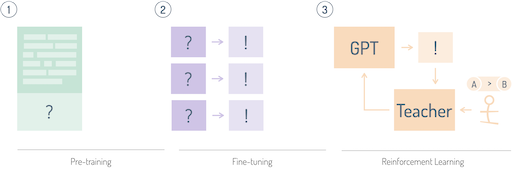
Le pipeline de formation d'entreprise
Construire un modèle prêt pour la production comme GPT-4o ou Claude 3.5/4 implique trois étapes sophistiquées :
- Pré-entraînement auto-supervisé : Le modèle "lit" le web ouvert et des ensembles de données privés pour apprendre la structure du langage, la logique, et même la programmation de base.
- Affinage par instruction : Le modèle est entraîné sur des paires soigneusement sélectionnées de questions et réponses. Cela enseigne à l'IA comment se comporter en tant qu'assistant utile plutôt que comme un simple compléteur de texte.
- Alignement des préférences (RLHF & DPO) : En utilisant des techniques comme l'apprentissage par renforcement à partir des retours humains (RLHF), le modèle est "polished" par des testeurs humains qui classent les réponses. Cela garantit que l'IA reste sûre, utile et alignée avec les valeurs de l'entreprise.
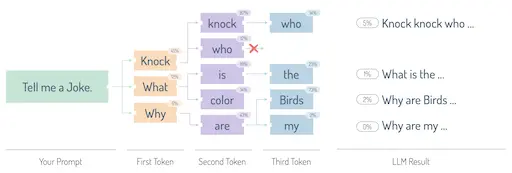
Génération auto-régressive & échantillonnage
Lors de la génération d'une réponse, l'IA utilise la génération auto-régressive — prédisant le prochain jeton en se basant sur tous les jetons précédents de la séquence. Pour éviter que l'IA soit trop répétitive ou « robotique », nous utilisons des techniques d'échantillonnage (comme Top-P et Température).
Ajuster la Température permet aux utilisateurs professionnels de basculer entre « Précision » et « Créativité ». Une température basse (0,1) est idéale pour les résumés juridiques ou l'extraction de données, tandis qu'une température élevée (0,8+) est préférable pour le brainstorming de slogans marketing ou l'écriture créative.
Préparer votre entreprise pour l'avenir : au-delà du chatbot
En 2026, la véritable valeur de l'IA générative réside dans la génération augmentée par récupération (RAG) et les agents IA. La RAG permet à l'IA de "consulter" les données privées et en temps réel de votre entreprise avant de répondre, éliminant ainsi pratiquement les hallucinations. Par ailleurs, les agents IA peuvent désormais exécuter des tâches de manière autonome — comme organiser des réunions, mettre à jour les CRM ou écrire et déployer du code.
La mise en œuvre de ces technologies ne concerne pas seulement l'efficacité ; il s'agit de construire un fossé évolutif et axé sur les données autour de votre entreprise. Comprendre ces fondamentaux vous garantit de pouvoir guider votre organisation à travers la transition vers l'IA en toute confiance.
L'avenir du travail n'est pas seulement assisté par l'IA — il en est accéléré.